LinkedHashMap是基于HashMap实现的子类,支持get, put等些基本操作O(1)时间复杂度的支持,允许null的mapping,但与HashMap不同的一点是,其支持按照mapping被添加进来的顺序进行遍历(底层使用额外的双链表储存了各个被添加的元素)。还有特殊的一点,如果该map是以access-ordered方式构建的,可以用来构建简单的LRU(最近最少使用)的缓存,在满足一定条件时,map 自动淘汰一些过期元素
基本描述
- 基于
HashMap和双链表并且具有可预知遍历顺序的Map接口实现,遍历顺序与mapping被添加进来时的顺序一致。跟HashMap不同之处在于,它维护一个运行于所有实体中的双链表,该链表定义了遍历的顺序 - 需要注意的是,如果重新插入一个
key,插入顺序不会受到影响(这里指的应该是accessOrder=false的情景) - 提供一个特别的构造方法,能够提供遍历顺序按照最少使用(
least-recently)到最常使用(most-recently),这种类型的Map比较符合构建LRU缓存的需求。removeEldestEntry(Map.Entry)方法可能需要被重写,从而在有新的mapping增加时,提供一个策略来自动删除比较旧的元素 - 跟HashMap类似,允许空的元素,一些基本的操作
(add, contains and remove)提供常量时间的性能,对比于HashMap,因为维护双链表需要开销,不过性能只稍微低于HashMap(不过有一个地方除外: 全局遍历的性能比HashMap的要好,LinkedHashMap只需要遍历链表,而HashMap需要遍历整个桶) - 非同步,可使用装饰模式
Map m = Collections.synchronizedMap(new LinkedHashMap(...))将其转换为同步的map - 在迭代遍历Map时,如果map内部结构发生修改,则会引起
fail-fast,抛出ConcurrentModificationException异常。特别的一点,具有访问顺序(access-ordered)要求的map,仅仅是简单的查询方法例如:get函数也会引起内部结构的变化
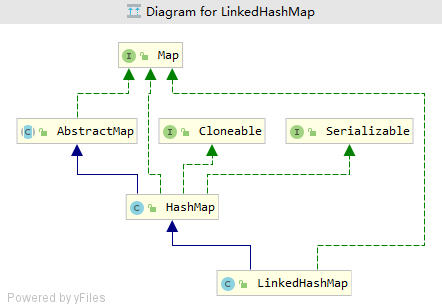
类图结构
内部数据结构
依次插入如下数据,假设key: “Math”, “English”经过hash函数处理后被映射到下标1上,Key: “Chinese”映射在下标4上
1 | LinkedHashMap<String, String> map = new LinkedHashMap<>(); |
在LinkedHashMap内部,里面桶以及双链表的结构如下图:
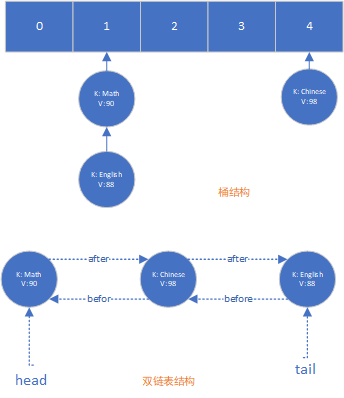
遍历map时,将直接遍历双链表,顺序与被插入的顺序一致:
1 | {"Math"="90", "Chinese"="98", "English"="88"} |
源码分析
双链表节点数据结构
1 | static class Entry<K,V> extends HashMap.Node<K,V> { |
- 基于
HashMap.Node,新增属性before,after - 使用双链表的一个好处是节点能够在删除时,不需要跟其它的节点关联,例如删除节点e,假设e的前后序节点都不为空,可直接这样进行删除:
1 | // 将e节点的前序节点的next指针指向e节点的后续节点 |
linkNodeLast(LinkedHashMap.Entry<K,V> p)函数
将当前节点p添加到双链表的尾部
1 | /** |
transferLinks(LinkedHashMap.Entry<K,V> src, LinkedHashMap.Entry<K,V> dst)
在由普通节点(pain node)转树节点(tree node)或者树节点转普通节点后,更新双链表中对应节点的旧节点信息为新的节点信息
1 | private void transferLinks(LinkedHashMap.Entry<K,V> src, |
afterNodeRemoval(Node<K,V> e)
在删除桶中对应的node节点后被调用,用来清除双链表对应的节点
1 | void afterNodeRemoval(Node<K,V> e) { // unlink |
afterNodeInsertion(boolean evict)
当有新的元素插入时执行,若满足removeEldestEntry时,则会删除LinkedHashMap中双链表对应的首个元素(从buckets和double-linked list结构中分别清除)
1 | void afterNodeInsertion(boolean evict) { // possibly remove eldest |
evict 参数的理解: 是否清除元素,只有在初始化构造map时(例如: 反序列,使用Map参数类型的构造方法创建对象)为false,其它时候为trues
afterNodeAccess(Node<K,V> e)
在元素被访问后(get,put等些方法)将其放置到双链表的尾部
1 | void afterNodeAccess(Node<K,V> e) { // move node to last |
利用LinkedHashMap实现简单的LRU缓存
问题描述: LeetCode LRU Cache
基于LinkedHashMap实现:
1 | class LRUCache { |
注: 当然感兴趣的话,也可以自己实现个双链表结构,基于HashMap实现类似的LRU缓存
参考资料
jdk-11.0.2